
Life's a garden. Dig it.
Challenge¶
Above Average (with too many people to fit in this title) is one of Tom Scott's least viewed videos. Use the YouTube Data API to fetch the comments for it.
Solution¶
from googleapiclient.discovery import build
# Instantiate a googleapiclient.discovery.Resource object for youtube
youtube = build(
serviceName='youtube',
version='v3',
developerKey='YOURAPIKEY'
)
# List to store response objects
responses = []
# Get the first response
request = youtube.commentThreads().list(
part="id,replies,snippet",
videoId="RAgbu7eDm44",
maxResults=50
)
response = request.execute()
responses.append(response)
# Iterate until the "current" response doesn't have nextPageToken
while "nextPageToken" in response:
request = youtube.commentThreads().list(
part="id,replies,snippet",
videoId="RAgbu7eDm44",
maxResults=50,
pageToken=response['nextPageToken']
)
response = request.execute()
responses.append(response)
# Close the connection
youtube.close()
# Flatten the nested items lists
comments = [item for response in responses for item in response['items']]
print(len(comments)) # 733
print(comments[:2])
# [{
# 'kind': 'youtube#commentThread',
# 'etag': 'fSxJ1wYXzsIkknsChM9kdeZ7M3c',
# 'id': 'UgxQFSezwzKiYZ89oeN4AaABAg',
# 'snippet': {
# 'videoId': 'RAgbu7eDm44',
# 'topLevelComment': {
# 'kind': 'youtube#comment',
# 'etag': 'YGeZBmanjw-4Ma8LV7Xl4lJLkwE',
# 'id': 'UgxQFSezwzKiYZ89oeN4AaABAg',
# 'snippet': {
# 'videoId': 'RAgbu7eDm44',
# 'textDisplay': 'Thank you for the bleeping you get a like from me :)',
# 'textOriginal': 'Thank you for the bleeping you get a like from me :)',
# 'authorDisplayName': 'Its Just Me',
# 'authorProfileImageUrl': 'https://yt3.ggpht.com/ytc/AMLnZu8Kq0GMCFF6i7H-Zi2xENLJ-WKAfx0d1W721zibtA=s48-c-k-c0x00ffffff-no-rj',
# 'authorChannelUrl': 'http://www.youtube.com/channel/UCC5D6f8TnwScJPyoMb6nH8Q',
# 'authorChannelId': {'value': 'UCC5D6f8TnwScJPyoMb6nH8Q'},
# 'canRate': True,
# 'viewerRating': 'none',
# 'likeCount': 0,
# 'publishedAt': '2022-10-22T05:36:15Z',
# 'updatedAt': '2022-10-22T05:36:15Z'
# }
# },
# 'canReply': True,
# 'totalReplyCount': 0,
# 'isPublic': True
# }
# },
# {
# 'kind': 'youtube#commentThread',
# 'etag': 'SY7Z81ZqW4EYzvA8tKVWjPsfCAQ',
# 'id': 'Ugw-e3np0WRASSx6AaV4AaABAg',
# 'snippet': {
# 'videoId': 'RAgbu7eDm44',
# 'topLevelComment': {
# 'kind': 'youtube#comment',
# 'etag': '40z16CIXMToouOSjTmYa8pJ2JCY',
# 'id': 'Ugw-e3np0WRASSx6AaV4AaABAg',
# 'snippet': {
# 'videoId': 'RAgbu7eDm44',
# 'textDisplay': 'so saf is going to burry them<br><br>barry em saf!!!',
# 'textOriginal': 'so saf is going to burry them\n\nbarry em saf!!!',
# 'authorDisplayName': 'PD Foltin',
# 'authorProfileImageUrl': 'https://yt3.ggpht.com/ytc/AMLnZu-T4fC57C_30yR_-WDAsrfHqi2JDoPLZ_ZUtw=s48-c-k-c0x00ffffff-no-rj',
# 'authorChannelUrl': 'http://www.youtube.com/channel/UCU_lwiWKRTUfiJifFFUSs-Q',
# 'authorChannelId': {'value': 'UCU_lwiWKRTUfiJifFFUSs-Q'},
# 'canRate': True,
# 'viewerRating': 'none',
# 'likeCount': 0,
# 'publishedAt': '2022-10-11T18:41:48Z',
# 'updatedAt': '2022-10-11T18:41:48Z'
# }
# },
# 'canReply': True,
# 'totalReplyCount': 0,
# 'isPublic': True
# }
# }]Explanation
Our solution is very similar to our solution for 3Blue1Brown.
We use the commentThreads.list resource to fetch all comment threads for videoId="RAgbu7eDm44". Since there are >50 comment threads, we paginate through the results. As long as our response has a nextPageToken, we make a subsequent call to youtube.commentThreads().list() with that token passed in.
while "nextPageToken" in response:
request = youtube.commentThreads().list(
part="id,replies,snippet",
videoId="RAgbu7eDm44",
maxResults=50,
pageToken=response['nextPageToken']
)
response = request.execute()
responses.append(response)Comment Data
The interesting part about this solution is the data that's returned - specifically how YouTube stores comment data. Browsing through the comments, you'll notice that top-level comments often have nested replies. But the replies themselves don't have nested replies. In other words,
- Each top-level comment begins a new comment thread.
- Comment threads can be up to 1 level deep with replies.
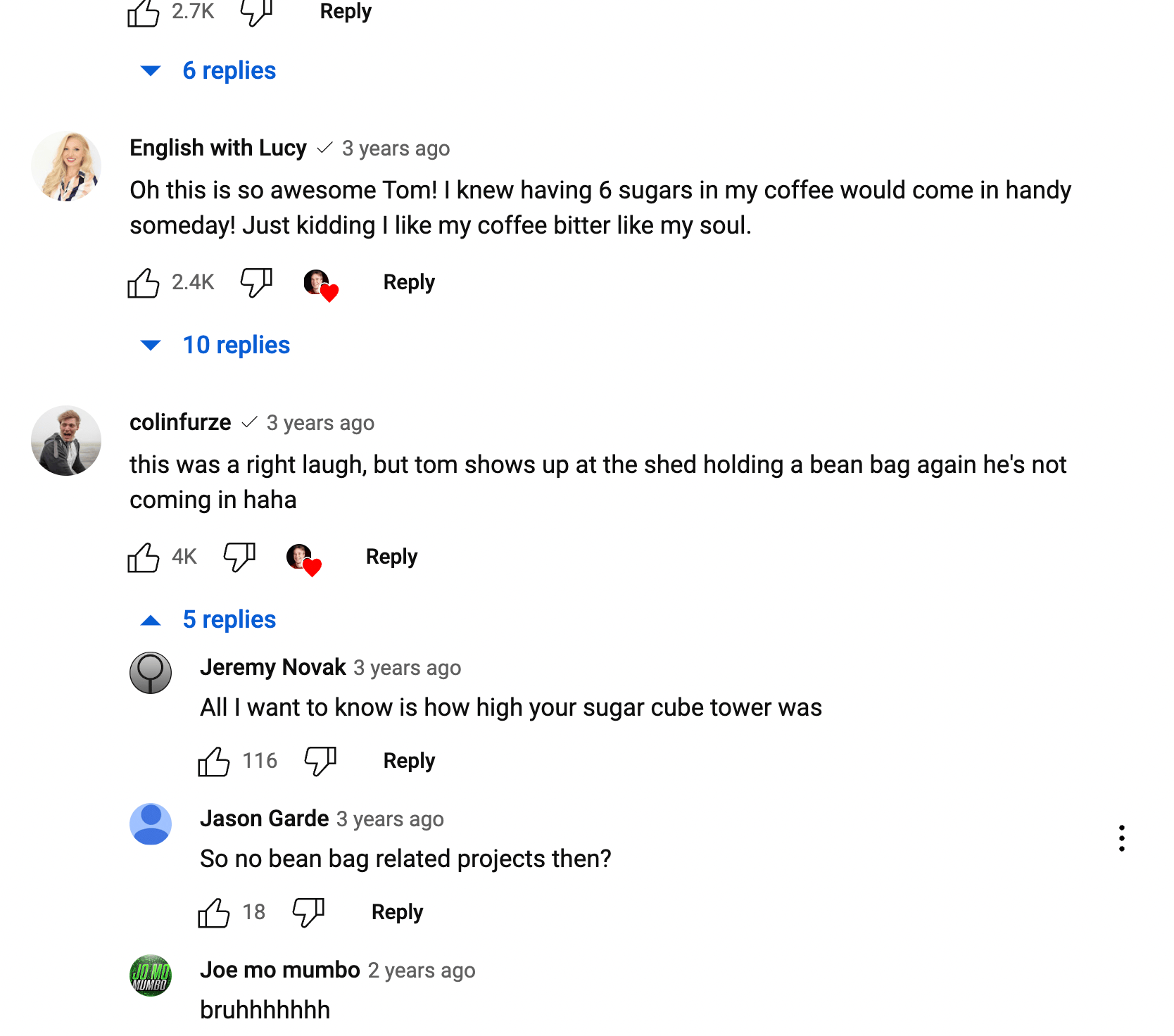
You can find examples of nested comments in the response data by searching for threads where totalReplyCount > 0.
for i in range(len(comments)):
if comments[i]['snippet']['totalReplyCount'] > 0:
print(comments[i])
break
# {
# 'kind': 'youtube#commentThread',
# 'etag': 'LFzEL87hqKuVP7eY6CwKpe9Ff9w',
# 'id': 'UgwK1qDvQrxEYPrFpbh4AaABAg',
# 'snippet': {
# 'videoId': 'RAgbu7eDm44',
# 'topLevelComment': {
# 'kind': 'youtube#comment',
# 'etag': '19yIxnIyH3PmkM2vFFvaHijq2xI',
# 'id': 'UgwK1qDvQrxEYPrFpbh4AaABAg',
# 'snippet': {
# 'videoId': 'RAgbu7eDm44',
# 'textDisplay': 'What average are you using? Mean or Median?',
# 'textOriginal': 'What average are you using? Mean or Median?',
# 'authorDisplayName': 'Franchello',
# 'authorProfileImageUrl': 'https://yt3.ggpht.com/ytc/AMLnZu-sHbsZVQN_2-vQjxuucox50YHkl4Io_jQlZg=s48-c-k-c0x00ffffff-no-rj',
# 'authorChannelUrl': 'http://www.youtube.com/channel/UC1ZfxwIph6iG53tSVTlFWCg',
# 'authorChannelId': {'value': 'UC1ZfxwIph6iG53tSVTlFWCg'},
# 'canRate': True,
# 'viewerRating': 'none',
# 'likeCount': 0,
# 'publishedAt': '2019-11-04T00:40:38Z', 'updatedAt': '2019-11-04T00:40:38Z'}
# },
# 'canReply': True,
# 'totalReplyCount': 1,
# 'isPublic': True
# },
# 'replies': {
# 'comments': [{
# 'kind': 'youtube#comment',
# 'etag': 'iv8OPAA0O0STzvlpD_NTNDEKp3E',
# 'id': 'UgwK1qDvQrxEYPrFpbh4AaABAg.90tcWSuHSoz96XKLsygOcg',
# 'snippet': {
# 'videoId': 'RAgbu7eDm44',
# 'textDisplay': 'What are you talking about?<br>Average = Mean<br>Median is a different statistic.',
# 'textOriginal': 'What are you talking about?\nAverage = Mean\nMedian is a different statistic.',
# 'parentId': 'UgwK1qDvQrxEYPrFpbh4AaABAg',
# 'authorDisplayName': 'K Veeder',
# 'authorProfileImageUrl': 'https://yt3.ggpht.com/ytc/AMLnZu-zU21V4i6KjAQhiSKA8XCZgkYC6U_rz56-SEzuvKk=s48-c-k-c0x00ffffff-no-rj'
# 'authorChannelUrl': 'http://www.youtube.com/channel/UClnu_HmKxXImV-N5UiVDULQ',
# 'authorChannelId': {'value': 'UClnu_HmKxXImV-N5UiVDULQ'},
# 'canRate': True, 'viewerRating':
# 'none', 'likeCount': 0,
# 'publishedAt': '2020-03-23T02:39:00Z',
# 'updatedAt': '2020-03-23T02:39:00Z'
# }
# }]
# }
# }