
Life's a garden. Dig it.
Challenge¶

3Blue1Brown is a YouTube channel by Grant Sanderson with some combination of math and entertainment, depending on your disposition.
Use the YouTube Data API to identify all the videos published by 3Blue1Brown. Get the id and publish date of every video.
Bonus Challenge
Determine how much quota cost you spent running this query.
Solution¶
As of writing, 3Blue1Brown has 127 videos with the following ids and published dates.
| | videoId | videoPublishedAt |
|----:|:------------|:---------------------|
| 0 | KuXjwB4LzSA | 2022-11-18T16:00:39Z |
| 1 | 851U557j6HE | 2022-11-04T15:54:19Z |
| 2 | cDofhN-RJqg | 2022-10-01T19:23:52Z |
| 3 | VYQVlVoWoPY | 2022-07-03T15:03:56Z |
| 4 | hZuYICAEN9Y | 2022-06-09T05:18:39Z |
| ... | ... | ... |
| 122 | -9OUyo8NFZg | 2015-06-21T06:05:43Z |
| 123 | K8P8uFahAgc | 2015-05-24T05:25:09Z |
| 124 | 84hEmGHw3J8 | 2015-04-11T08:19:03Z |
| 125 | zLzLxVeqdQg | 2015-03-05T06:15:23Z |
| 126 | F_0yfvm0UoU | 2015-03-05T06:15:22Z |Our basic strategy for solving this is
- Find the channel id
- Query the
channels.listresource to get the channel's uploads video playlist id. - Query the
playlistItems.listresource to get the videos and their details.
1. Find the channel id
Here's what the 3Blue1Brown channel homepage looks like.
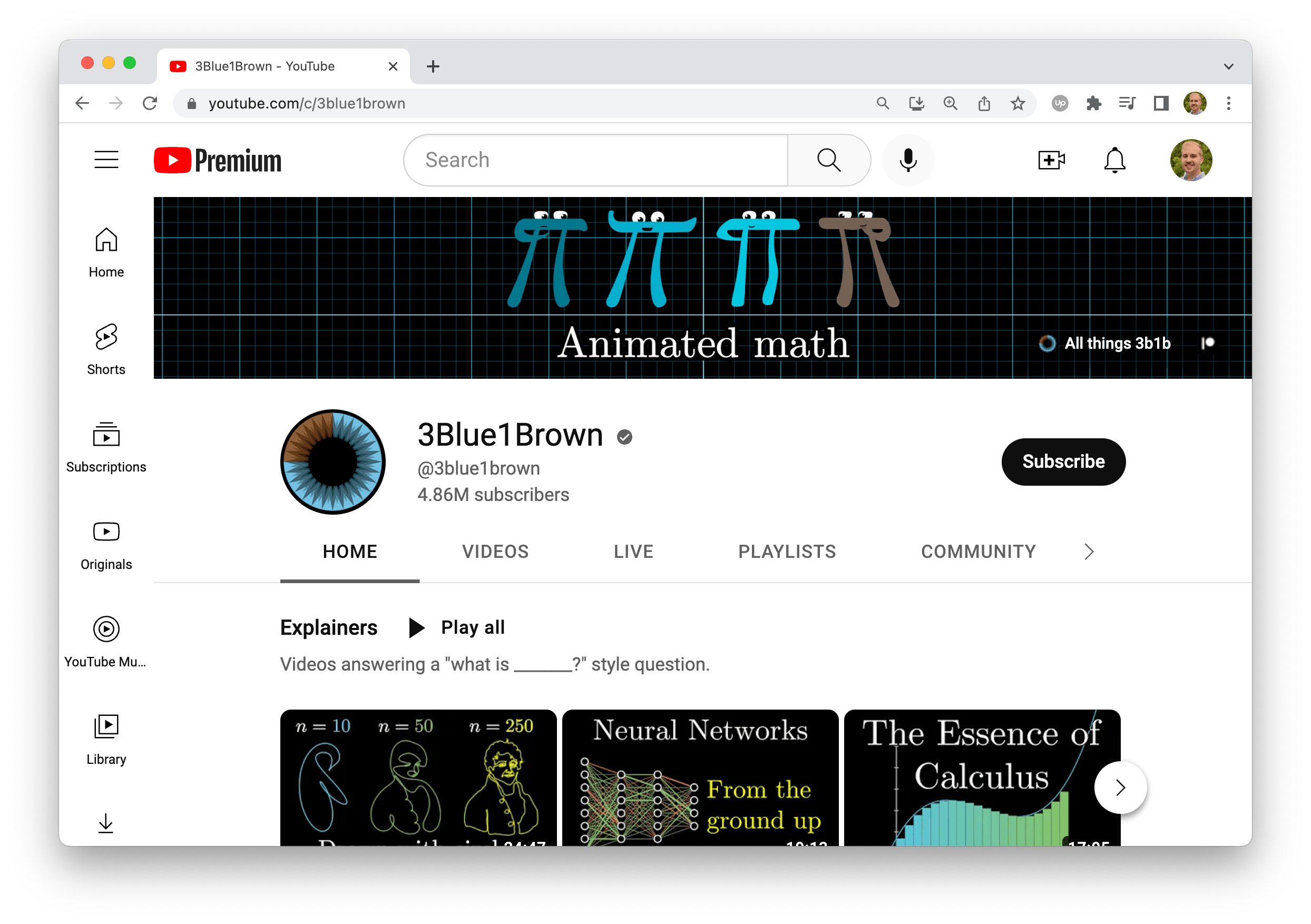
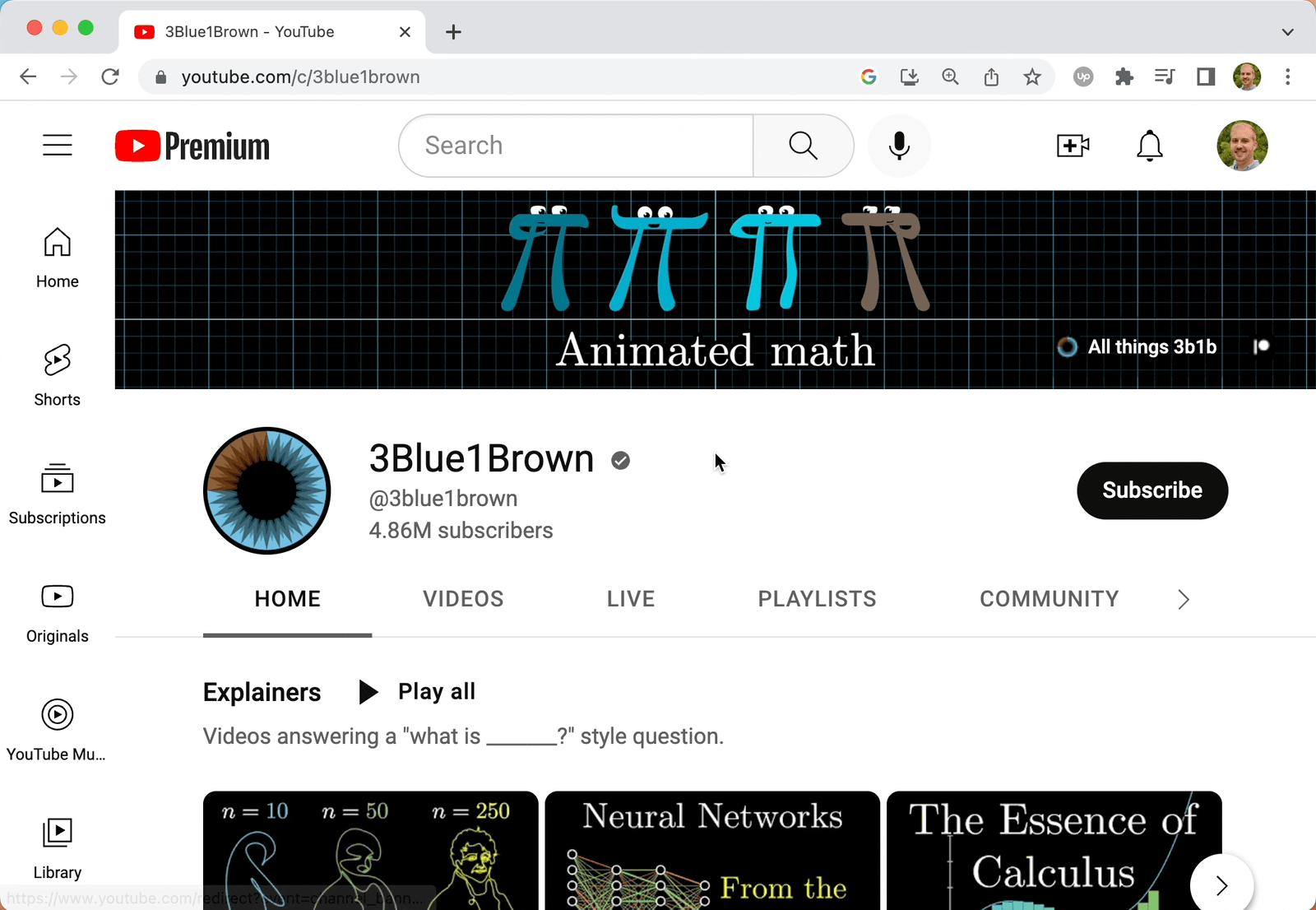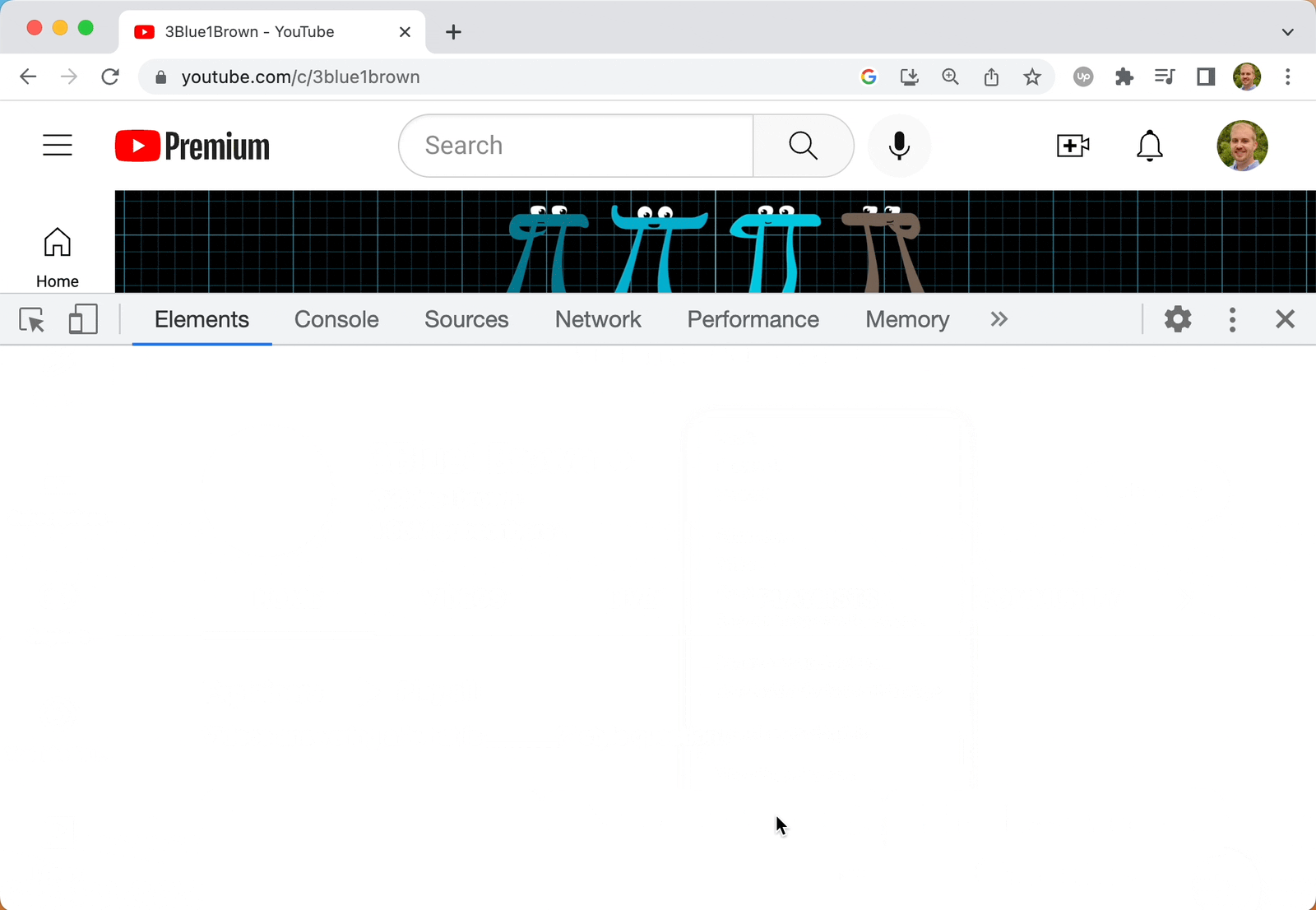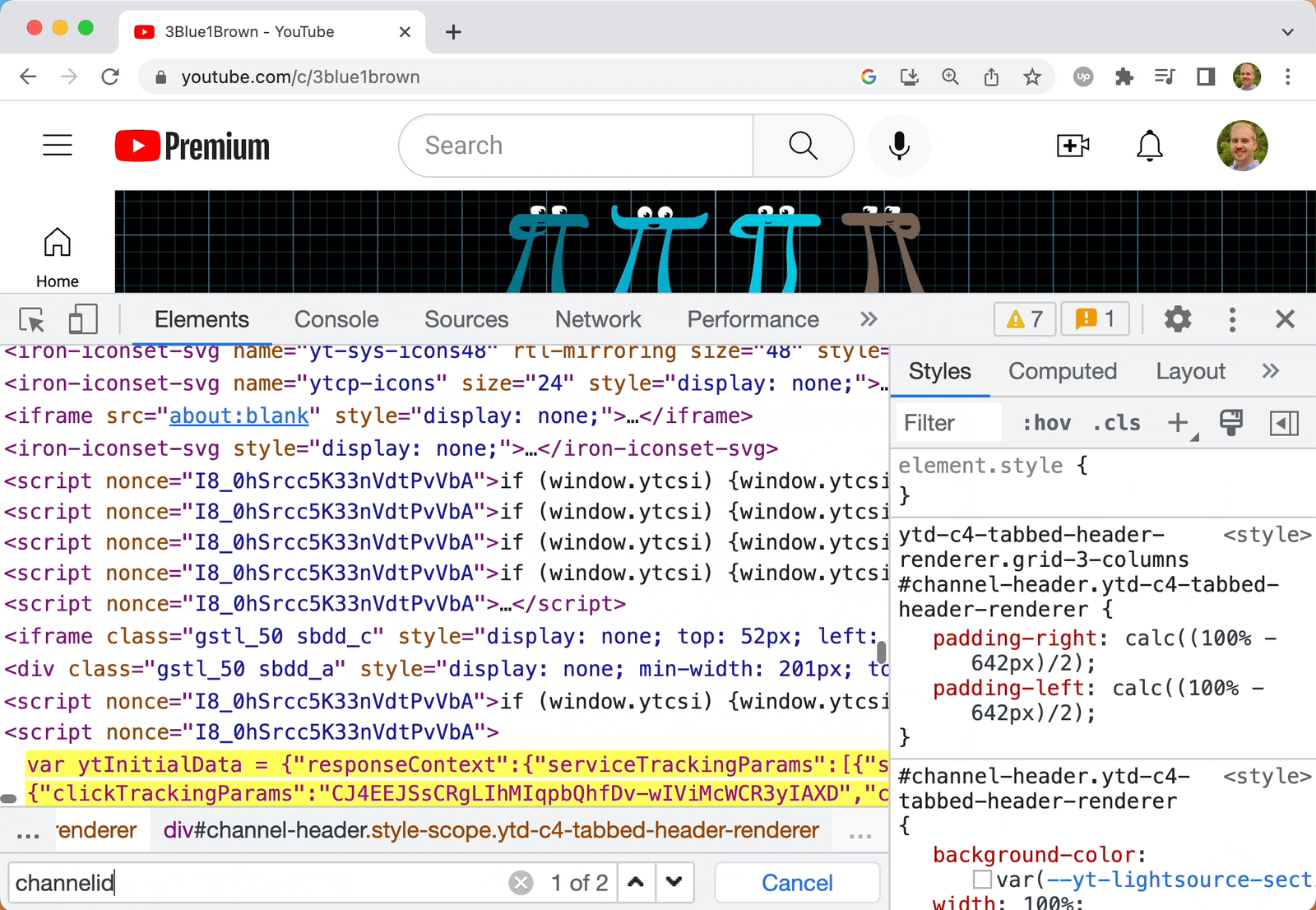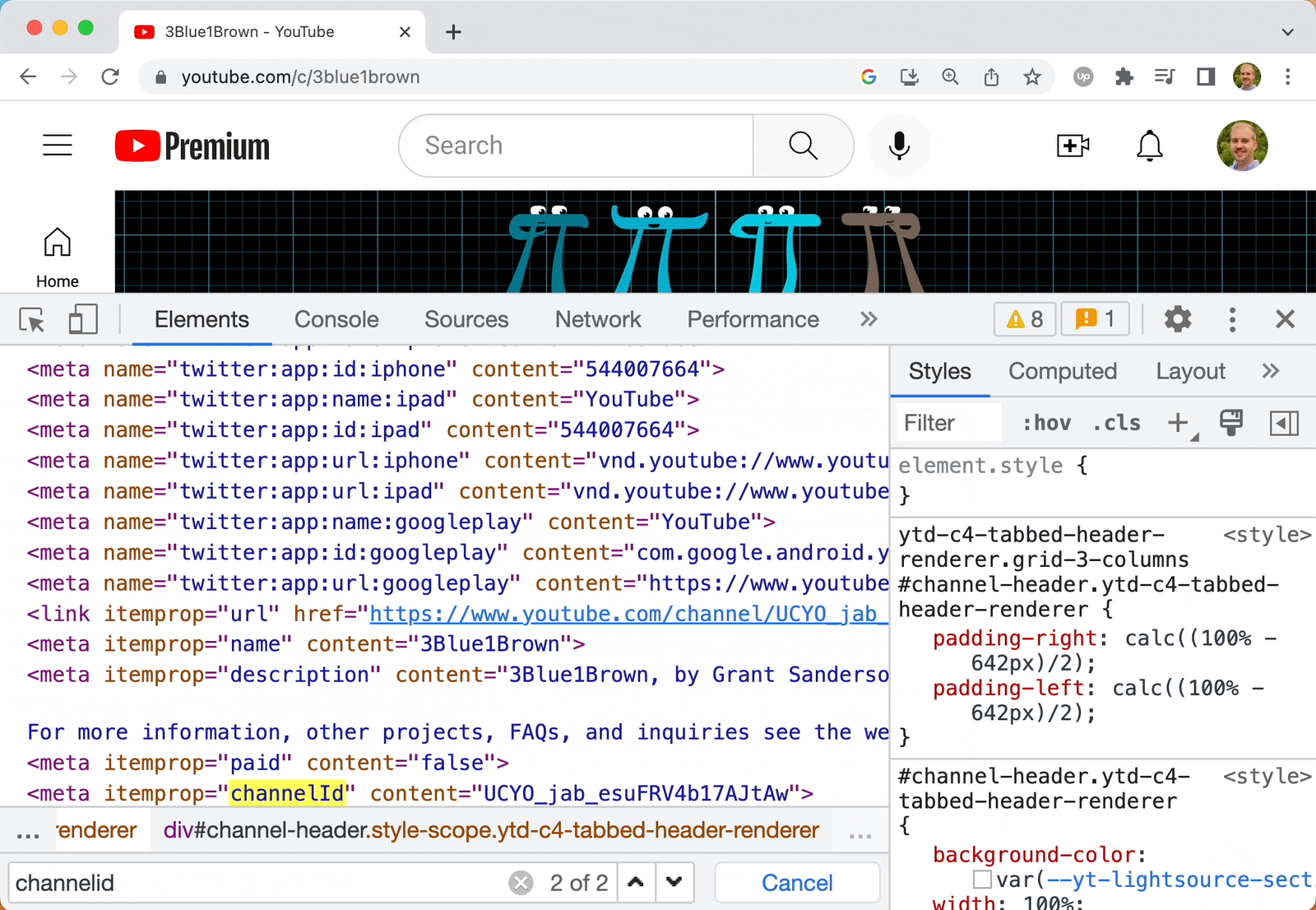
In order to user the channels.list resource to to get details about this channel, we need to know the channel id or username. You might assume the channel username is 3blue1brown but it's not. Fortunately, we can dig up the channel id from the page source code.
2. Query the channel to get the uploads playlist id
Now we can fetch the uploads playlist id by querying the channel with part=contentDetails.
from googleapiclient.discovery import build
# Instantiate a googleapiclient.discovery.Resource object for youtube
youtube = build(
serviceName='youtube',
version='v3',
developerKey='YOURAPIKEY'
)
# Define the request
request = youtube.channels().list(
part="contentDetails",
id="UCYO_jab_esuFRV4b17AJtAw"
)
# Execute the request and save the response
response = request.execute()
item = response['items'][0]
print(item)
# {
# 'kind': 'youtube#channel',
# 'etag': 'EwjSlH5iJ9ppD-Xc1oIjCTQAplI',
# 'id': 'UCYO_jab_esuFRV4b17AJtAw',
# 'contentDetails': {
# 'relatedPlaylists': {
# 'likes': '',
# {=='uploads': 'UUYO_jab_esuFRV4b17AJtAw'==}
# }
# }
# }We'll store that id for future use.
# Get the uploads id
uploads_id = item['contentDetails']['relatedPlaylists']['uploads']
print(uploads_id)
# 'UUYO_jab_esuFRV4b17AJtAw'3. Query the playlist to get the videos
Now we can use the playlistItems.list resource to pull the videos.
# Define the request
request = youtube.playlistItems().list(
part="id",
playlistId=uploads_id
)
# Execute the request and save the response
response = request.execute()
print(response)
# {
# 'kind': 'youtube#playlistItemListResponse',
# 'etag': '7CNZUOtQMZt4GH6XjqpKT93IZCM',
# 'nextPageToken': 'EAAaBlBUOkNBVQ',
# 'items': [
# {
# 'kind': 'youtube#playlistItem',
# 'etag': 'SM0r_MTB5khM9qyohQXUaGrto-E',
# 'id': 'VVVZT19qYWJfZXN1RlJWNGIxN0FKdEF3Lkt1WGp3QjRMelNB'
# },
# {
# 'kind': 'youtube#playlistItem',
# 'etag': '-zGUjA3p5NpJVbH0MCVrruCTB-I',
# 'id': 'VVVZT19qYWJfZXN1RlJWNGIxN0FKdEF3Ljg1MVU1NTdqNkhF'
# },
# {
# 'kind': 'youtube#playlistItem',
# 'etag': 'CRcDRYDcCSCurzFjJcX8rp1qcJg',
# 'id': 'VVVZT19qYWJfZXN1RlJWNGIxN0FKdEF3LmNEb2ZoTi1SSnFn'
# },
# {
# 'kind': 'youtube#playlistItem',
# 'etag': 'ZS48gxOSnrotIBJqkqtG-nssQDY',
# 'id': 'VVVZT19qYWJfZXN1RlJWNGIxN0FKdEF3LlZZUVZsVm9Xb1BZ'
# },
# {
# 'kind': 'youtube#playlistItem',
# 'etag': 'W_SkVS953APebs1zxg4zC0-D0wk',
# 'id': 'VVVZT19qYWJfZXN1RlJWNGIxN0FKdEF3LmhadVlJQ0FFTjlZ'
# }
# ],
# {=='pageInfo': {'totalResults': 127, 'resultsPerPage': 5}==}
# }Here we use part="id", so all we get back are the video ids. (We'll improve this later). Notice we get back 5 of 127 items.
By default, the YouTube data API returns up to 5 items. We can tell it to return up to 50 items per response with maxResults=50.
Pagination
Even when we set maxResults=50, we still need to make multiple requests to fetch all 127 videos. In other words, we need to paginate the responses using the nextPageToken.
# List to store response objects
responses = []
# Get the first response
request = youtube.playlistItems().list(
part="id",
playlistId=uploads_id,
maxResults=50,
)
response = request.execute()
responses.append(response)
# Iterate until the "current" response doesn't have nextPageToken
while "nextPageToken" in response:
request = youtube.playlistItems().list(
part="id",
playlistId=uploads_id,
maxResults=50,
pageToken=response['nextPageToken']
)
response = request.execute()
responses.append(response)Then we can flatten the nested items lists like this
items = [item for response in responses for item in response['items']]
print(len(items)) # 127Now we just need to change part="id" to part="contentDetails" to fetch the right data.
# List to store response objects
responses = []
# Get the first response
request = youtube.playlistItems().list(
part="contentDetails",
playlistId=uploads_id,
maxResults=50,
)
response = request.execute()
responses.append(response)
# Iterate until the "current" response doesn't have nextPageToken
while "nextPageToken" in response:
request = youtube.playlistItems().list(
part="contentDetails",
playlistId=uploads_id,
maxResults=50,
pageToken=response['nextPageToken']
)
response = request.execute()
responses.append(response)
# Flatten the nested items lists
items = [item for response in responses for item in response['items']]Let's inspect the first item.
print(items[0])
# {
# 'kind': 'youtube#playlistItem',
# 'etag': 'Y9hx774pHfdy3znSH2fZ7M6k7Uw',
# 'contentDetails': {
# 'videoId': 'KuXjwB4LzSA',
# 'videoPublishedAt': '2022-11-18T16:00:39Z'
# }
# }We've successfully pulled video ids and publish dates 🥳
How can I format the data as a table?
Use Python Pandas.
import pandas as pd
df = pd.DataFrame([x['contentDetails'] for x in items])
print(df)Check out our Pandas problem set to learn more about it.
See the full code for this example
Bonus Challenge
The total cost of this query is 4 quota.
- 1 request to
channels.listx 1 quota per request = 1 quota - 3 requests to
playlistItems.listx 1 quota per request = 3 quota
See here for the quota cost reference table.
Why don't you just use search.list?
We could fetch all videos from 3Blue1Brown using search.list, but each call to search.list costs 100 quota :face_vomiting: so it'd be a very expensive query!
See the code