
In today's data-driven world, organisations continuously seek to leverage data for strategic decision-making and to gain competitive advantages. However, the true value of data often lies not in its raw form, but in how it is transformed and utilised leading to a more accurate and actionable insights.

This is where feature engineering comes into play, a crucial process in data analytics that enhances the data and the power of algorithms to produce more accurate predictions and actionable insights.
Feature engineering involves the transformation of raw data into a structured format that highlights the most relevant and meaningful aspects of the underlying problem or phenomenon being analysed. By reducing noise and amplifying signal quality, this process directly influences the performance of predictive models, making it an indispensable element for organisations looking to improve their analytical capabilities.
This article will delve into the key components of feature engineering, breaking down its role in data transformation, the creation of meaningful feature sets, and the ways it impacts the development of predictive models that lead to better decision-making. For business leaders and C-level executives, understanding feature engineering is essential for ensuring that data-driven strategies are built on solid, high-quality foundations.
Feature Engineering: What is it?¶
Feature engineering is the process of transforming data into a feature set in a structured format that efficiently and effectively represents the underlying domain's problem or phenomenon being analysed. This process enhances the performance of analytics algorithms and their resulting models by reducing noise and improving signal quality, ultimately leading to more accurate predictions and actionable insights.
Let’s break down the previous definition further and examine precisely what feature engineering entails:
-
Process of Transforming Data: Features engineering can be applied at any stage of the data lifecycle on data that has already been processed and somewhat cleaned and organised, or on data in its most raw form, e.g. server logs, emails, social media content, multimedia files, chat messages, sensor data, webpages, etc. At the end, the data will be organised in a structured tabular format, consisting of rows (observations) and columns (attributes). It is important to note that feature engineering is not limited to structured data; it can also be applied to semi-structured and unstructured data in typical scenarios.
-
Feature Set: The feature set consists of meaningful attributes of the data that contribute to improving the analytic process. When working with tabular data, we often diagnose which columns serve as features (signal: providing valuable information for analysis, and which are merely attributes; noise: offering little to no predictive power or relevance).
-
Efficiently and Effectively Represents the Underlying Domain's Problem or Phenomenon: The data is always intended to represent a specific problem within a particular domain. It is crucial to maintain focus on the broader context while applying feature engineering techniques. Our goal is to transform the data in a way that enhances its ability to accurately reflect the larger problem at hand, ensuring that the insights derived from the analysis are relevant and actionable.
-
Reducing Noise and Improving Signal Quality: In the context of feature engineering, reducing noise refers to the process of eliminating irrelevant or redundant data (unimportant attributes) that can obscure meaningful patterns and insights. Improving signal quality involves enhancing the meaningful information (informative attributes) within the dataset that is relevant to the problem being analysed. By focusing on high-quality signals, analysts can develop more robust predictive models that yield accurate predictions and actionable insights.
-
Accurate Predictions: In data analytics, accurate predictions refer to the ability of a model to make correct forecasts about future outcomes based on historical data, leading to models that can generalise well to new, unseen data.
-
Actionable Insights: They are the valuable understandings and interpretations by revealing patterns, trends, and relationships within the data derived from analysing data, helping stakeholders make informed decisions with clarity and direction by addressing business questions or challenges.
A tip
Ultimately, the combination of accurate predictions and actionable insights is essential for organisations seeking to leverage data-driven strategies, laying groundwork for robust analytics algorithms and models that not only predict outcomes with high precision but also provide clarity and direction for decision-making.
In summary:¶
Feature engineering is the process of identify and transforming data into features sets that better represent the underlying problem, resulting in improved predictive model performance.
Feature Engineering: Its Steps¶
Feature engineering is a crucial step in the data analytics process, significantly impacting the performance of predictive models. It involves transforming dataset into meaningful features sets that enhance the predictive power of algorithms. The following outlines a structured approach to feature engineering, detailing each step in the process.
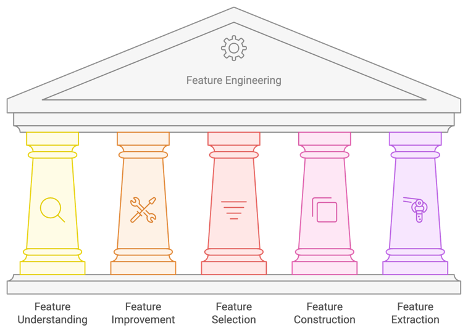
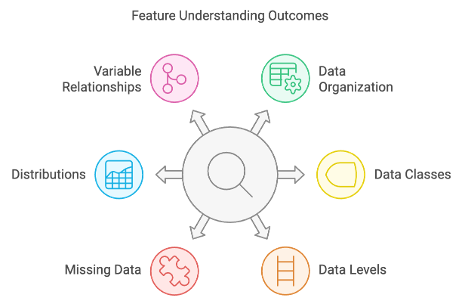
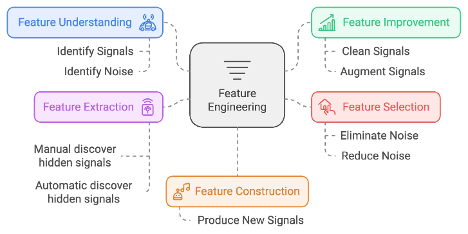
- Feature Understanding: The first step involves a thorough exploration and identification of existing features and their characteristics the dataset has. This includes identify and understand data organisation, data classes, data levels, missing data, distributions, and potential relationships among variables.
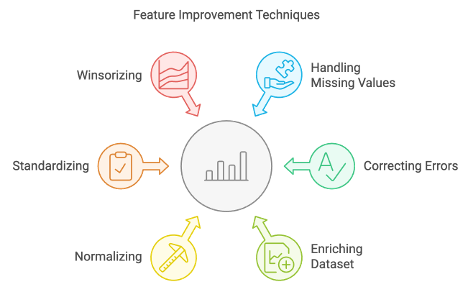
- Feature Improvement: Once familiar with the dataset, the next phase focuses on cleaning and augmenting signals (features). This may involve handling missing values, correcting errors, and enriching the dataset with additional relevant information, normalise, standardise, winsorizing or winsorization (outliers), etc.
- Feature Selection: In this step, it's essential to assess which features contribute meaningfully to the model's performance. Unnecessary or irrelevant attributes are eliminated to streamline the dataset and reduce noise.

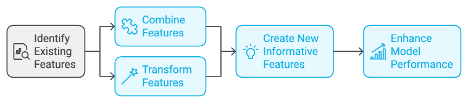
- Feature Construction: This phase encourages creativity in building new features from existing ones. By combining or transforming current attributes, analysts can create more informative features that better capture underlying patterns.
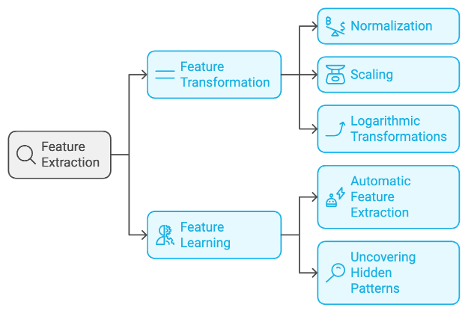
- Feature Extraction: This step encompasses two sub-processes:
- 5.1 Feature Transformation: Mathematical techniques are applied to modify existing features, via manual feature extraction, making them more suitable for modelling. This can include, but not limited to, normalisation, scaling, applying logarithmic transformations, etc.
- 5.2 Feature Learning: Leveraging artificial intelligence techniques allows for automatic feature extraction from complex datasets, enhancing model performance by uncovering hidden patterns.
In summary:¶
Feature engineering steps are all about dividing datasets in two subsets: signal (features: meaningful attributes) and noise (meaningless or insignificant attributes). Signals must be boosted and noise eliminated or reduced to the minimum, leading to improve the qualities of predictive models to be produced.
Feature Engineering: Where it happens?¶
In the context of the article, feature engineering happens after the data gathering and before the model training, validation because it serves as the crucial intermediary step that transforms raw, collected data (signals and noise mixed) into a structured and meaningful format that enhances model performance. Once data is gathered, it is often unstructured, messy, or incomplete, requiring careful cleaning and organisation. This is where feature engineering comes in. It refines the raw data into a usable structured format by selecting, transforming, and creating new features (or attributes) that better represent the underlying problem or domain. Without this step, even the most advanced models may fail to produce accurate results because they rely heavily on the quality and relevance of the input features.
The following table shows the general steps of both data gathering and feature engineering:
Data Preparation: Steps and Sub-steps Sequence
| #1. Data Gathering: | #2. Feature Engineering |
|---|---|
| 1. Define the Objective | 2.1. Feature Understanding |
| 2. Identify Data Sources | 2.2. Feature Improvement |
| 3. Data Collection | 2.3. Feature Selection |
| 4. Data Preprocessing | 2.4. Feature Construction |
| 5. Data Validation | 2.5. Feature Extraction |
| 6. Data Storage | . 2.5.1. Feature Transformation |
| . 2.5.2. Feature Learning |
In summary:¶
Think in ‘general’ as data gathering being more enterprise-oriented, while feature engineering being more project-oriented.
Feature Engineering Challenges¶
Although feature engineering can be summarised – finding and identifying signals and noise in a dataset, amplifying signals and eliminating noise with the goal of improving the qualities of predictive models – there are many difficulties and challenges inherent to this process. To name a few challenges:
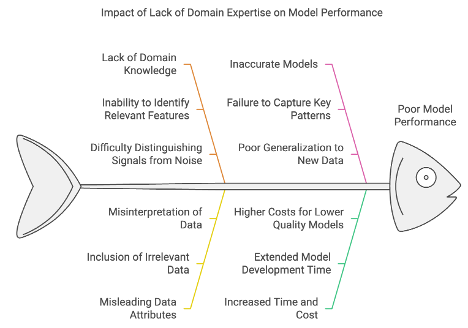
• Domain Knowledge Expertise
Domain expertise is crucial for understanding the context and nuances of the problem being addressed, helping to identify which data attributes are ‘relevant and meaningful’ (i.e. signal a.k.a. feature). Without this knowledge, it's difficult to distinguish between important signals and unnecessary, misleading and irrelevant noise. The absence of domain knowledge expertise can significantly impact the quality and relevance of the features created, leading to poor model performance. This can result in inaccurate models that fail to capture key patterns, provide actionable insights, or generalise well to new data, ultimately hindering decision-making and business outcomes, and increased time and cost to produce the predictive model with lower quality.
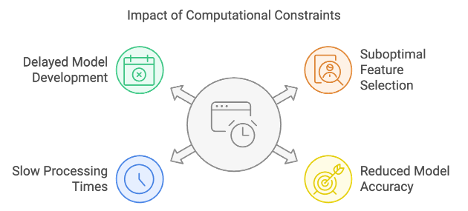
• Computational and Resource Constraints
Large datasets, complex models, data transformations, normalisation, unstructured data, deep learning, among other demand a lot of computational power, memory, cycles, storage, network, etc... Constraints on computational power and resources can hinder the feature engineering process. Suboptimal feature selection and less accurate predictive models, ultimately impact the overall performance and scalability of data-driven solutions with slow processing times, extended iteration cycles, reduced ability to experiment with different features sets, leading to delays in model development.
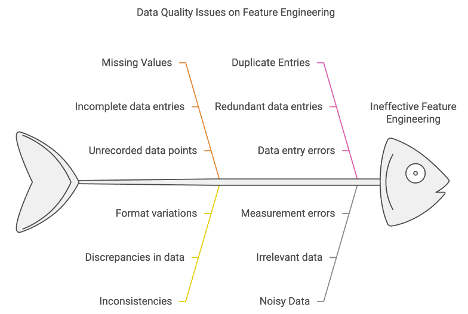
• Data Quality Issues
Effective feature engineering is only possible when data is clean, consistent, and well-prepared. The quality of the raw data has a profound impact on feature engineering directly influencing the effectiveness of the features created. Poor data quality makes it difficult to accurately capture the underlying signals necessary for building strong predictive models, potentially introducing bias, errors, or irrelevant noise into the model. Common problems such as missing values, inconsistencies, duplicate entries, and noisy data can obscure meaningful patterns and lead to the development of flawed features. This results in reduced model accuracy, diminished predictive power, and unreliable insights, ultimately affecting decision-making and the overall success of data-driven projects.
• Handling Different Data Types
Structured data (e.g., tabular data with well-defined rows and columns), semi-structured (e.g., XML, HTML, JSON, E-Mail, logs files, etc.) and unstructured data (e.g., text, images, videos, audio, etc.) requires different techniques for cleaning, transforming, and integrating them into a unified dataset, introduce significant complexity and challenges, negatively impacting the process. This complexity increases the risk of inconsistencies, misinterpretations, and improper transformations, which can lead to the creation of ineffective or misleading features. Handling different data types in feature engineering and failing to handle these differences appropriately can result in reduced model accuracy, poor predictive performance, and longer development times.
• Model Underfitting
Underfitting is caused by a model that is too simple to capture the underlying patterns in the data. It's like using a straight line to describe something more complex, like a curve. Because the model is too basic, insufficiently trained, etc., it can't capture important details, and as a result, it performs poorly both on trained on and on new, unseen data. This leads to inaccurate predictions and poor overall performance.
• Model Overfitting
Overfitting is caused by a model that is too complex and learns not only the underlying patterns but also the noise and random fluctuations in the training data. In simple terms, the model learns the training data too well. This leads to poor predictions in real-world situations outside of the training data. Too many features, in special irrelevant and redundant features can cause the model to learn noise rather than meaningful patterns. Insufficient training data can lead to poor generalisations, and excessive training time can lead to ‘pedantic models’ that focus on minutes details, instead of focusing on the big picture.
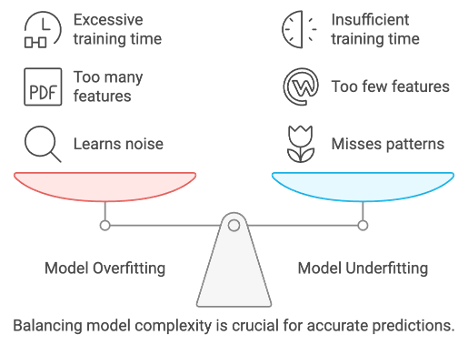
• Balancing bias and variance
In feature engineering is critical for building models that generalize well to new data. When the model has high bias, it tends to underfit, as it becomes too simplistic to capture the complexities of the data, leading to poor performance on both the training data and new, unseen data. On the other hand, high variance can result in overfitting, where the model becomes too complex, learning not only the meaningful patterns but also the noise present in the training data. The goal in feature engineering is to find the right level of complexity by selecting and transforming features that capture the true underlying patterns while avoiding irrelevant details. This requires careful judgment to avoid adding too many features, which could lead to overfitting, or using too few, which could lead to underfitting. Ultimately, the challenge lies in crafting features that strike the right balance, allowing the model to generalise well to new data without becoming overly simplistic or overly detailed.
In summary:¶
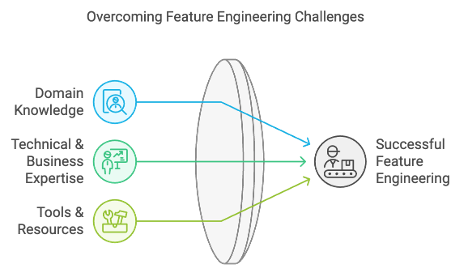
Overcoming these difficulties requires a combination of domain knowledge, technical & business expertise, and access to appropriate tools and resources.
Conclusion¶
Feature engineering is all about dividing datasets into two subsets: signal and noise. Signals must be boosted and noise eliminated, leading to improvements in the quality of predictive models that provide reliable forecasts and empower organisations to support informed decisions, drive strategic initiatives, and foster competitive advantages in their markets. Easy to say, but hard to achieve...
The path to effective feature engineering is fraught with challenges. To name a few: domain knowledge is paramount; without it, organisations risk misidentifying signals and noise within their datasets. Additionally, computational constraints can hinder the ability to experiment with various feature sets, while data quality issues can obscure meaningful patterns and lead to flawed insights. Addressing these challenges requires a concerted effort that combines technical expertise with business expertise to understand the problem context.
In the rapidly evolving landscape of data analytics, feature engineering is an important step for organisations aiming to harness the full predictive potential of their data. A well-trained predictive model is characterised by accuracy, generalisation capability, interpretability, robustness to noise and variance, scalability, flexibility, low bias, and timeliness. These qualities collectively empower organisations to make informed decisions based on reliable forecasts, ultimately driving strategic initiatives and fostering competitive advantages in their respective markets.
For C-level executives, technical managers and business managers, recognising the importance of feature engineering is vital. It serves as the bridge between the collected data and the predictive models that support effective decision-making. High-quality features lead to robust models that can generalise well to new data, ultimately driving better business outcomes. The insights derived from well-engineered features empower organisations to make informed decisions, optimise operations, and innovate in their respective markets.
Moreover, organisations must be vigilant about balancing bias and variance in their models. Striking this balance is essential to avoid underfitting or overfitting – two pitfalls that can severely compromise model performance. By carefully selecting and transforming features, businesses can create models that capture true underlying patterns without being misled by irrelevant details.
In conclusion, feature engineering is not just a technical task; it is a strategic initiative that can determine an organisation's success in leveraging data for competitive advantage. By investing in robust feature engineering practices, businesses can ensure that their data-driven strategies are built on solid foundations. This commitment will not only enhance predictive accuracy but also provide clarity and direction for decision-making in an increasingly complex business environment. As we move forward in this data-driven era, embracing feature engineering will be key to unlocking new opportunities and achieving sustainable growth.
Article References¶
-
THE THREE SEXY SKILLS OF DATA GEEKS https://medriscoll.com/2009/05/27/the-three-sexy-skills-of-data-geeks/
-
DATA PREP STILL DOMINATES DATA SCIENTISTS’ TIME, SURVEY FINDS https://www.datanami.com/2020/07/06/data-prep-still-dominates-data-scientists-time-survey-finds/
-
SURVEY SHOWS DATA SCIENTISTS SPEND MOST OF THEIR TIME CLEANING DATA https://www.dataversity.net/survey-shows-data-scientists-spend-time-cleaning-data/
-
HOW DO DATA PROFESSIONALS SPEND THEIR TIME ON DATA SCIENCE PROJECTS? https://businessoverbroadway.com/2019/02/19/how-do-data-professionals-spend-their-time-on-data-science-projects/
-
DATA SCIENTISTS SPEND MOST OF THEIR TIME CLEANING DATA https://whatsthebigdata.com/data-scientists-spend-most-of-their-time-cleaning-data/
Book References¶
-
Feature Engineering Bookcamp
- AUTHOR: Sinan Ozdemir
- PUBLISHED BY: Manning Publications
- PUBLICATION DATE: September 2022
- PAGES: 272 pages
-
Python Feature Engineering Cookbook - Third Edition
- AUTHOR: Soledad Galli
- PUBLISHED BY: Packt Publishing
- PUBLICATION DATE: August 2024
- PAGES: 396 pages
-
Feature Engineering Made Easy Identify Unique Features from Your Dataset in Order to Build Powerful Machine Learning Systems
- AUTHOR(S): Sinan Ozdemir, Divya Susarla
- PUBLISHED BY: Packt Publishing
- PUBLISHED DATE: January 2018
- PAGES: 316 pages
-
FEATURE STORE FOR MACHINE LEARNING Curate, Discover, Share and Serve ML Features at Scale
- AUTHOR(S): Jayanth Kumar M J
- PUBLISHED BY: Packt Publishing
- PUBLISHED DATE: June 2022
- PAGES: 280 pages