
Life's a garden. Dig it.
Challenge¶
Which digits below represent the number 2?
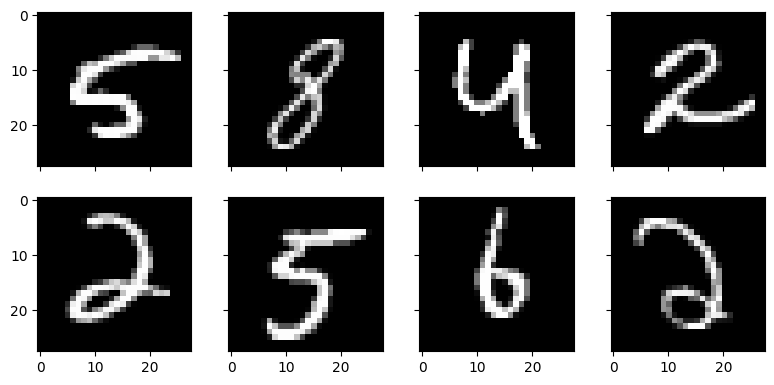
Easy peasy! But can you write a program to classify 2s like these?
In this challenge, your task is to implement a Perceptron to classify handwritten 2s using the famous MNIST dataset. In other words, your model should be able to look at an image and say "this is a two" or "this is not a two".
Data¶
You can download the MNIST image files from the Kaggle dataset MNIST as PNG. The unzipped file hierarchy looks like this 👇
test/
0/
test_image_3.png
test_image_10.png
test_image_13.png
...
1/
test_image_2.png
test_image_5.png
test_image_14.png
...
...
9/
train/
0/
train_image_1.png
train_image_21.png
train_image_34.png
...
1/
...
9/
Every image file is a 28x28 grayscale image of a handwritten digit (0 - 9).
test/Need help getting started?
Weights and bias¶
Select the best weights and bias by implementing a guess-and-check algorithm. In other words,
- Randomly choose weights and a bias.
- Measure the model's performance (accuracy) on the training data.
- Repeat this process a few thousand times, keeping track of the best performing weights and bias.
Review the model¶
Regarding your best model,
-
Which pixel adds the most evidence that the image represents a 2 as it becomes lighter? Explain why this makes intuitive sense.
-
Which pixel adds the most evidence that the image represents a 2 as it becomes darker? Explain why this makes intuitive sense.
Solution¶
import glob
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
# Define constants
TRAINPATH = "/Users/bgorman/Datasets/mnist-png/train"
TESTPATH = "/Users/bgorman/Datasets/mnist-png/test"
# Random number generator
RNG = np.random.default_rng(2024)
def load_images(path):
"""
Given a path, recursively identify all PNG files below the path and load
them into a list of PIL Images
Args:
path (str): Directory path like 'pics/whales/'
Returns:
tuple(list[Image], list[str]): Returns a 2-element tuple. The first element
is a list of Image instances. The second is a list of corresponding filenames
"""
images = []
filepaths = []
for filename in glob.glob(f"{path}/**/*.png"):
im = Image.open(filename)
images.append(im)
filepaths.append(filename)
return images, filepaths
# Load the data
trainX, trainFiles = load_images(TRAINPATH)
testX, testFiles = load_images(TESTPATH)
# Determine the training data labels
trainY = np.array([file.split("/")[-2] for file in trainFiles])
testY = np.array([file.split("/")[-2] for file in testFiles])
# Convert list of Images to arrays with float64 vals
trainX = np.array(trainX, dtype="float64")
testX = np.array(testX, dtype="float64")
# Standardize the data
trainX = trainX / 255
testX = testX / 255
# Declare the model
class Perceptron:
def __init__(self, w, b):
self.w = w
self.b = b
def predict(self, X):
if X.ndim == 2:
z = np.sum(X.reshape((1, -1)) * self.w) + self.b
elif X.ndim == 3:
z = np.sum(X.reshape((len(X), -1)) * self.w, axis=1) + self.b
return z >= 0
# Keep track of the best weights and bias
best = {"accuracy": 0.0, "w": None, "b": None}
# Find optimal weights + bias
for i in range(5000):
if i % 1000 == 0:
print("Iteration", i)
# Pick random weights and bias
w = RNG.uniform(-1, 1, size=784)
b = RNG.uniform(-20, 20)
# Train the Perceptron
perceptron = Perceptron(w, b)
# Predict on the training data
preds = perceptron.predict(trainX)
# Measure the accuracy rate
accuracy = np.mean(preds == (trainY == "2"))
# Check if best
if accuracy > best["accuracy"]:
print("New best accuracy:", accuracy)
best["accuracy"] = accuracy
best["w"] = w
best["b"] = bAfter 5,000 iterations, the best model classifies 2s with ~91% accuracy on the training data and ~90% accuracy on the test data.
View the output
View the selected weights and bias
Model Review
We can identify out the most important pixels by finding the index of the positive and negative weights with the greatest magnitude.
print(np.argmax(best['w'])) # 582 ==> (20, 22)
print(np.argmin(best['w'])) # 214 ==> (7, 18)In this case, the model implies
- lightening pixel
(20, 22)adds the most evidence that the image is a 2 - darkening pixel
(7, 18)adds the most evidence that the image is a 2
Here are some example images with these pixels highlighted by green and red arrows.
![]()
The large positive weight for pixel (20, 22) makes intuitive sense because it locates the trailing tail of the number "2" - a pixel that is rarely activated by other numbers. Pixel (7, 18) appears to have a large negative weight because it's a popular pixel that's activated by many different numbers.